Jiva Overview
Jiva
Each Jiva Volume comprises of a Controller (or Target) and a set of Replicas. Both Controller and Replica functionalities are provided by the same binary and hence the same docker image. Jiva simulates a block device which is exposed via an iSCSI target implementation(gotgt - part of the Controller). This block device is discovered and mounted remotely on the host where application pod is running. The Jiva Controller parallelly replicates the incoming IOs to its replicas. The Replica, in turn, writes these IOs to a sparse file.
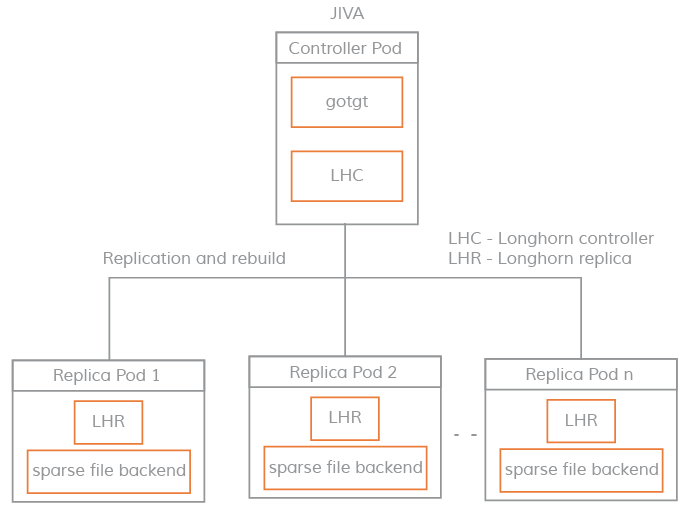
Jiva Sparse File Layout
The following content is modified with some architectural change as compared to Rancher's LongHorn documentation.
Replica Operations of Jiva
Jiva replicas are built using Linux sparse files, which support thin provisioning. Jiva does not maintain additional metadata to indicate which blocks are used. The block size is 4K. When a replica gets added at the controller, it creates an auto-generated snapshot(differencing disk). As the number of snapshots grows, the differencing disk chain could get quite long. To improve read performance, Jiva, therefore, maintains a read index table that records which differencing disk holds valid data for each 4K block. In the following figure, the volume has eight blocks. The read index table has eight entries and is filled up lazily as read operation takes place. A write operation writes the data on the latest file(head), deletes(fallocate) the corresponding block from the older snapshots(or differencing disks) and updates the index in the table, which now points to the live data.
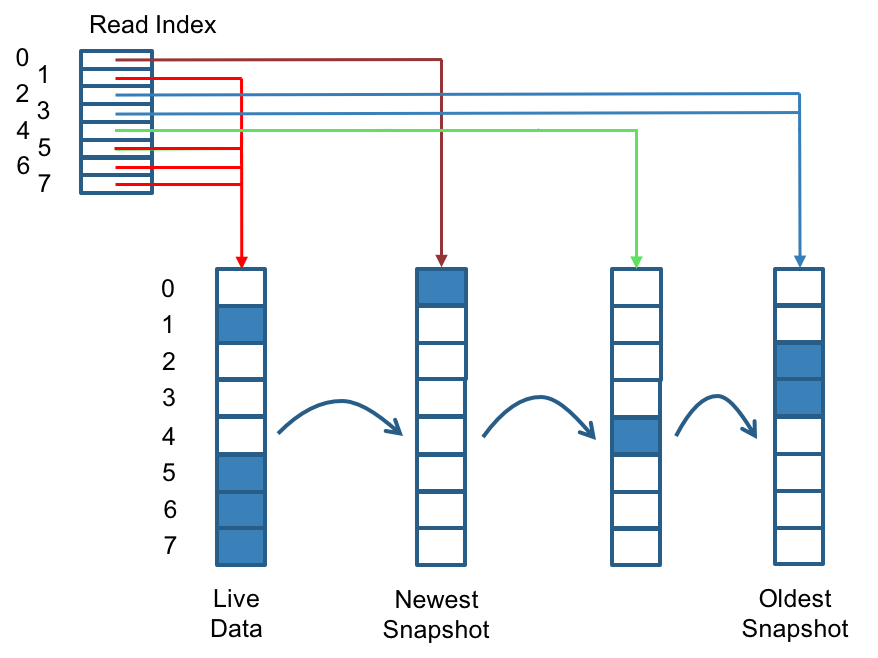
The read index table is kept in memory and consumes two bytes for each 4K block. A maximum of 512 auto-generated snapshots can be created for each volume. The read index table consumes a certain amount of in-memory space for each replica. A 1TB volume, for example, consumes 512MB of in-memory space.
Replica Rebuild
The Jiva volume controller is responsible for initiating and coordinating the process of syncing the replicas. Once a replica comes up, it tries to get added to controller and controller will mark it as WO(Write Only). Then the replica initiates the rebuilding process from other healthy replicas. After the sync is completed, the volume controller sets the new replica to RW (read-write) mode.
When the controller detects failures in one of its replicas, it marks the replica as being in an error state and the rebuilding process is triggered.
Note: If REPLICATION_FACTOR is still met even after a replica is marked faulty, the controller will continue to serve R/W IOs. Else, it will wait for satisfying REPLICATION_FACTOR((n/2)+1; where n is the number of replicas).
See Also:
Which storage engine should I use ?
Jiva User Guide
Feedback
Was this page helpful?
Thanks for the feedback. Open an issue in the GitHub repo if you want to report a problem or suggest an improvement. Engage and get additional help on https://kubernetes.slack.com/messages/openebs/.